Meta’s Full-stack HHVM optimizations for GenAI
- 작성일시
- 2025.07.08
- 작성자
- 경승현책임연구원
- HIT
- 4184

By Phil Lopreiato, Zach Zundel
메타는 생성형 AI(GenAI)를 활용한 새롭고 혁신적인 제품을 출시했기 때문에 기본 인프라 구성 요소가 함께 진화하도록 해야 합니다. 인프라 지식과 최적화를 적용함으로써 변화하는 제품 요구 사항에 적응할 수 있었고, 그 과정에서 더 나은 제품을 제공할 수 있었습니다. 궁극적으로 인프라 시스템은 고품질의 경험을 제공해야 하는 필요성과 시스템 지속 가능성을 실행해야 하는 필요성의 균형을 맞춰야 합니다.
GenAI 추론 트래픽을 전용 WWW 테넌트로 분할하여 특수한 런타임 및 워밍업 구성을 가능하게 함으로써 이 두 가지 목표를 모두 달성하는 동시에 지연 시간을 30% 개선할 수 있었습니다.
The changing landscape
고전적으로 Meta의 웹 서버는 웹페이지를 렌더링하고 GraphQL 쿼리를 처리하는 프론트엔드 요청에 최적화되어 있습니다. 이러한 요청의 지연 시간은 일반적으로 수백 밀리초에서 몇 초(30초 제한보다 상당히 낮음) 단위로 측정되므로 호스트는 초당 약 500개의 쿼리를 처리할 수 있습니다.
또한 웹 서버는 약 3분의 2의 시간을 입출력(I/O)에 소비하고 나머지 3분의 1은 CPU 작업에 소비합니다. 이러한 사실은 협력 멀티태스킹의 일종인 비동기 장치를 지원하는 핵 언어의 설계에 영향을 미쳤으며, 모든 핵심 라이브러리는 이러한 기본 요소를 지원하여 성능을 높이고 CPU가 유휴 상태로 있는 시간을 줄여 I/O를 기다립니다.
GenAI 제품, 특히 LLM에는 다양한 요구 사항이 있습니다. 이러한 요구 사항은 핵심 추론 흐름에 의해 주도됩니다: 모델은 완료하는 데 몇 초 또는 몇 분이 걸릴 수 있는 토큰 스트림으로 응답합니다. 사용자는 이를 챗봇이 응답을 "타이핑"하는 것으로 볼 수 있습니다. 이는 제품을 더 친근하게 보이게 하기 위한 효과가 아니라 모델이 생각하는 속도입니다! 사용자가 모델에 쿼리를 제출한 후에는 가능한 한 빨리 이러한 응답을 사용자에게 다시 스트리밍해야 합니다. 게다가 이제 요청의 총 지연 시간이 상당히 길어졌습니다(초 단위로 측정). 이러한 속성은 인프라에 두 가지 영향을 미치는데, 즉 LLM을 호출하기 전에 중요한 경로에 대한 오버헤드를 최소화하고 나머지 요청은 대부분 I/O에 대기하는 데 소요되는 긴 시간입니다(아래 그림 1 및 2 참조).
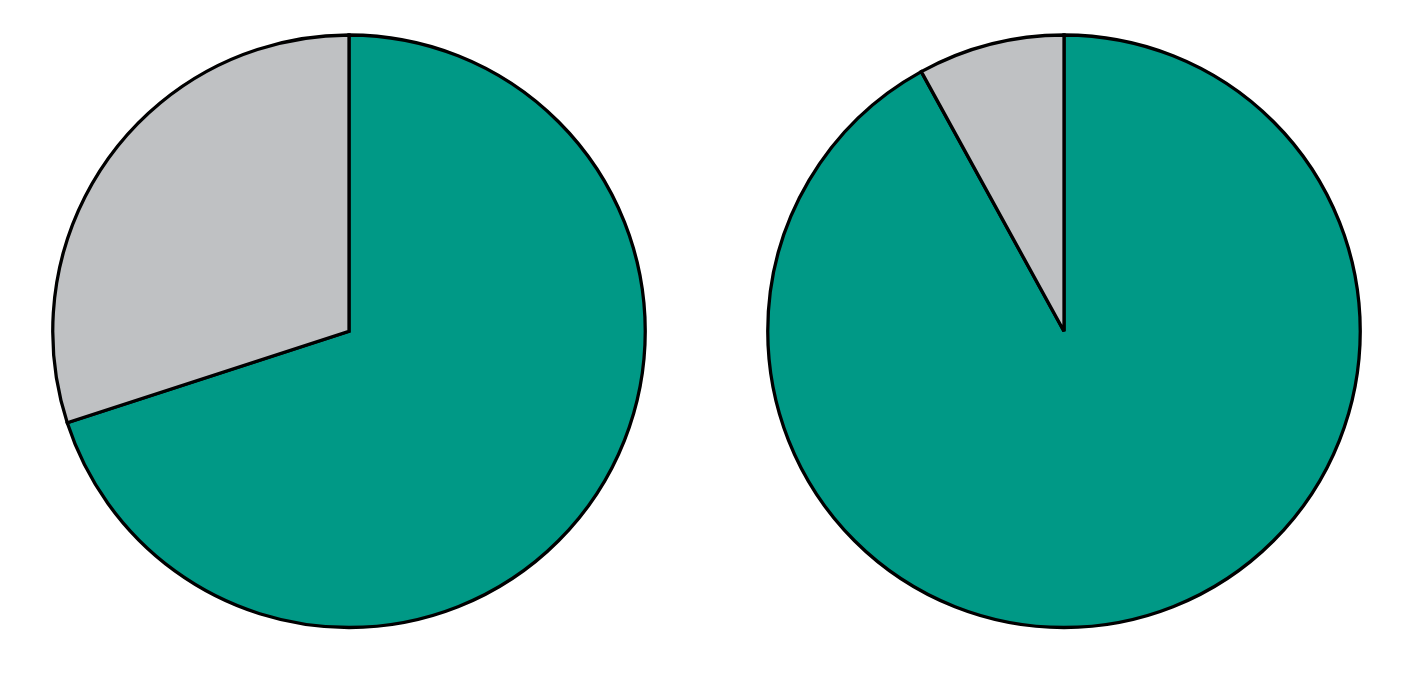
Figure 1: Percent of time spent on I/O, typical requests (~70%) vs. GenAI (~90%).
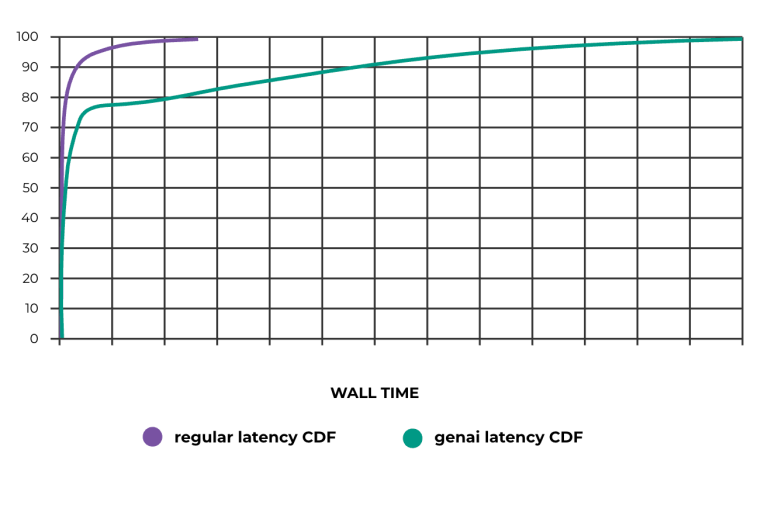
Figure 2: Overall request latency CDF; typical requests vs. GenAI.
A series of optimizations
이러한 요구 사항의 변화로 인해 웹 재단은 모놀리식 웹 계층을 실행하는 규칙을 재검토할 수 있게 되었습니다. 그런 다음 워크로드의 요구 사항을 더 잘 조정할 수 있는 맞춤형 구성을 허용하는 전용 웹 테넌트(WWW의 독립형 배포)를 출시했습니다.
Request timeout
첫째, 격리된 웹 계층에서 실행하면 GenAI 요청의 런타임 제한을 늘릴 수 있었습니다. 이는 간단한 변경 사항이지만, 운영 계층의 나머지 부분에 부정적인 영향을 미치지 않도록 더 오래 실행되는 트래픽을 격리할 수 있게 해주었습니다. 이렇게 하면 추론에 30초 이상 걸리는 경우 요청 타이밍을 피할 수 있습니다.
Thread-pool sizing
요청을 더 오래 실행하면 작업자 스레드의 가용성이 감소합니다(기억하세요, 처리된 요청과 1:1로 매핑). 웹서버의 메모리 양이 한정되어 있기 때문에, 요청당 메모리 제한으로 사용 가능한 총 메모리를 나누어 활성 요청의 최대 수를 얻을 수 있습니다. 이는 동시에 얼마나 많은 요청을 실행할 수 있는지를 알려줍니다. 결국 GenAI 호스트에서는 약 1000개의 스레드로 실행되었고, 일반 웹서버에서는 수백 개의 스레드로 실행되었습니다.
JIT cache and “jumpstart”
HHVM은 주어진 함수가 처음 실행될 때, 기계가 이를 하위 수준의 기계 코드로 컴파일하여 실행해야 하는 Just-in-Time (JIT) 해석 언어입니다. 또한 Jump-Start라는 기술을 통해 웹서버는 이전에 웜된 서버의 출력으로 JIT 캐시를 시드할 수 있습니다. GenAI 호스트가 메인 웹 계층에서 Jump-Start 프로필을 사용할 수 있도록 함으로써 코드 중복이 동일하지 않더라도 실행 속도를 크게 높일 수 있습니다.
Request warm-up
HHVM은 또한 서버 시작 시 더미 요청을 실행할 수 있도록 지원하며, 이를 실행한 후 결과를 폐기할 수 있습니다. 여기서의 목적은 웹서버 내에서 비코드 캐시를 웜하는 것입니다. 구성 값과 서비스 검색 정보는 일반적으로 처음 필요할 때 인라인으로 가져온 다음 웹서버 내에 캐시됩니다. 웜업 요청에서 이 정보를 가져오고 캐싱함으로써 사용자가 이러한 초기 가져오기의 지연 시간을 관찰하지 못하도록 합니다.
Shadow traffic
마지막으로, 메타는 기능 롤아웃을 제어하기 위해 실시간 구성을 많이 사용합니다. 이는 시작 시 소비되는 점프스타트 프로필이 서버가 실행할 모든 향후 코드 경로를 커버하지 못할 수 있음을 의미합니다. 정상 상태에서 커버리지를 유지하기 위해 요청 음영 처리도 추가하여 게이팅 변경 사항이 JIT 캐시에서 여전히 커버되도록 했습니다.
<출처 - Meta Engineering>
url : https://engineering.fb.com/2025/05/20/web/metas-full-stack-hhvm-optimizations-for-genai/